Not one system is going to put structure in your data, because it doesn't understand your research. The structure comes from you. | Patrick Vandewalle

Time invested in thinking about organising research data and the associated data and project documentation will pay off in the long term. It makes the data easier to find and understand. This section contains a number of tips on how to keep it structured.
Findable and understandable data
If you want research data to be findable and easy to interpret, then it is important to store the data in a structured, consistent manner and to provide it with the necessary data documentation and metadata. The folder structure in which the data ends up must speak for itself, as must the file names used for the data files (see box).
It is also possible for a researcher to use a system that already has a certain amount of structure in it. For example, a division into folders already exists. And when you upload data, you are asked for basic metadata, such as the author, date, and so on. Think of a virtual research environment, a tool such as Dataverse (DANS, n.d.) or some electronic lab journals.
Meaningful file names
Good file names provide useful guidance on the content, status and version of a file, uniquely identify a file, and help classify and sort it. Here you will find a few tips for storing filenames meaningfully and consistently (UK Data Service, 2017):
- Make sure that files are consistently named. For example, if you use the date in the filename, choose how to write the date (e.g. YYYYMMDD or yymmdd);
- Don't put strange characters such as ?\!@*%{[<> in the filename;
- Provide traceable file names, such as Project_Instrument_location_YYYMMDD.ext.;
- Make sure that each file name appears only once in the folder structure. If you save a file name in multiple places and you are going to edit one of them, there may be unintentional multiple versions of the same file;
- Make sure that the version of the file is in the file name;
- Use hyphens (-) or underscores (_) to separate elements in a file name;
- Avoid very long file names;
- Reserve the 3-letter file extension for application-specific codes of the file format (e.g. .doc, .xls, .mov, .tif).
It is good practice to explain the choice of file names and its meaning in a README.txt.
Even when a researcher is already well underway in his/her project, he/she can still switch to a consistent naming for filenames by using a so-called bulk file rename utility (n.d.)(Windows only). Of course, it's important to check if the bulk renamer delivers what it promises.

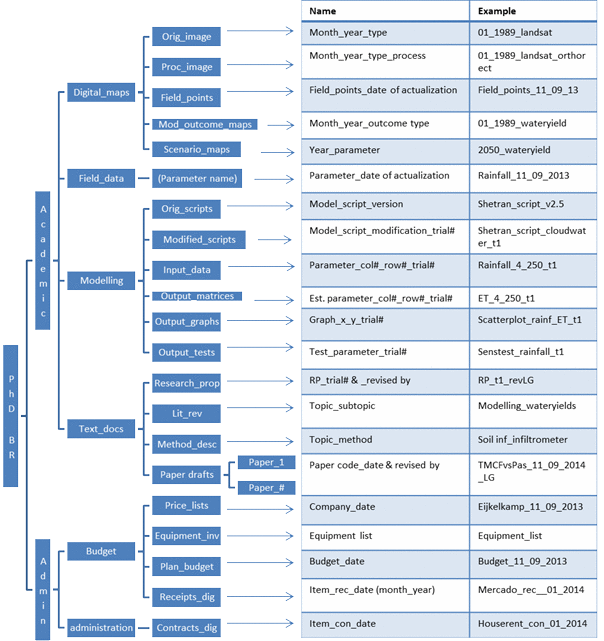
Example of a folder structure
Below you can see the proposed folder structure and file names for the research of Beatriz Ramirez that she made for her research at Wageningen University & Research.
The main challenge to data sharing is organising data in a presentable and useful way. | Stuart, 2018

Sources
Click to open/close
Apache (n.d.). Apache Subversion https://subversion.apache.org/
Backlog (2018, 4th of April). Git vs. SVN: Which version control system is right for you? https://backlog.com/blog/git-vs-svn-version-control-system/
Bulk Rename Utility (n.d.). https://www.bulkrenameutility.co.uk/Main_Intro.php
CESSDA (n.d.). Data Management Expert Guide. Data authenticity. https://www.cessda.eu/Training/Training-Resources/Library/Data-Management-Expert-Guide/3.-Process/Data-authenticity
DANS (n.d.). DataverseNL. https://dans.knaw.nl/nl/over/diensten/DataverseNL
Git (n.d.) https://git-scm.com/
GitHub (n.d.). https://github.com/
Patrick Vandewalle (n.d). http://pixeltje.be/
Stuart, David; Baynes, Grace; Hrynaszkiewicz, Iain; Allin, Katie; Penny, Dan; Lucraft, Mithu; et al. (2018): Whitepaper: Practical challenges for researchers in data sharing. figshare. Journal contribution. https://doi.org/10.6084/m9.figshare.5975011.v1
UK Data Service. (2017). Organising data. Retrieved from https://www.ukdataservice.ac.uk/manage-data/format/organising

