Organiseren van onderzoeksdata
Not one system is going to put structure in your data, because it doesn't understand your research. The structure comes from you | Patrick Vandewalle

Tijd die wordt geïnvesteerd in het nadenken over het organiseren van onderzoeksdata en de bijbehorende datadocumentatie en projectdocumentatie verdient zich op termijn dubbel en dwars terug. Het maakt de data namelijk makkelijker vindbaar en begrijpelijk. In deze paragraaf een aantal tips om de structuur erin te houden.
Vindbare en begrijpelijke data
Als je wilt dat onderzoeksdata vindbaar en makkelijk te interpreteren zijn en blijven, dan is het zaak de data op een gestructureerde, consequente manier op te slaan en te voorzien van de benodigde datadocumentatie en metadata. De folderstructuur waarin de data terecht komen, moet voor zich spreken, net zoals de bestandsnamen die voor de databestanden worden gebruikt (zie kader).
Het kan ook zo zijn dat een onderzoeker gebruik maakt van een systeem dat al een bepaalde mate van structuur in zich heeft. Er is bijvoorbeeld al een indeling in folders. En als je data uploadt wordt er om basis metadata gevraagd, zoals auteur, datum, enzovoort. Denk hierbij aan een virtuele onderzoeksomgeving, een tool zoals Dataverse (DANS, n.d.) of sommige elektronische labjournaals .
Betekenisvolle bestandsnamen
Goede bestandsnamen bieden nuttige aanwijzingen voor de inhoud, status en versie van een bestand, identificeren een bestand op unieke wijze en helpen bij het classificeren en sorteren van bestanden. Hieronder volgt een aantal tips om bestandsnamen betekenisvol en consistent op te slaan (UK Data Service, 2017):
- Zorg ervoor dat bestandsnamen consistent benoemd worden. Gebruik je bijvoorbeeld de datum in de bestandsnaam, kies dan hoe je de datum noteert (bijvoorbeeld YYYYMMDD of yymmdd);
- Plaats geen rare karakters zoals ?\!@*%{[<> in de bestandsnaam;
- Geef herleidbare bestandsnamen, zoals Project_Instrument_locatie_YYYYMMDD.ext.;
- Zorg ervoor dat elke bestandsnaam maar één keer in de folderstructuur voorkomt. Als je een bestandsnaam op meerdere plekken opslaat en je gaat één van beiden bewerken, dan kunnen er ongewild meerdere versies van hetzelfde bestand ontstaan;
- Zorg ervoor dat de versie van het bestand in de bestandsnaam staat;
- Gebruik koppeltekens (-) of onderstrepingstekens (_) om elementen in een bestandsnaam te scheiden;
- Vermijd zeer lange bestandsnamen;
- Reserveer de 3-letterige bestandsextensie voor toepassingsspecifieke codes van het bestandsformaat (bijv. .doc, .xls, .mov, .tif).
Het is good practice om de keuze voor een bestandsnaam en de betekenis daarvan toe te lichten in een README.txt.
Ook als een onderzoeker al een eind op weg is in zijn/haar project, kan hij/zij nog overgaan op een consistente naamgeving voor bestandsnamen door gebruik te maken van een zogeheten bulk file rename utility (n.d.). Het is wel zaak te checken of zo'n bulk renamer levert wat deze belooft.

Voorbeeld van een folderstructuur
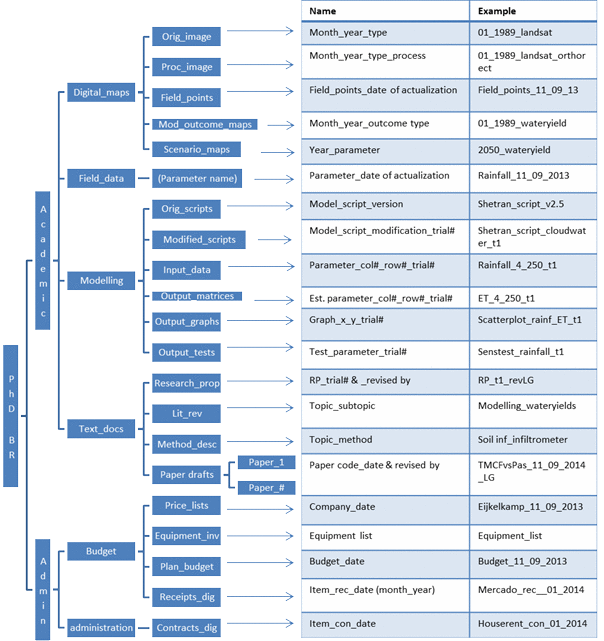
Hieronder zie je de voorgestelde folderstructuur en bestandsnamen voor het onderzoek van Beatriz Ramirez dat zij maakte voor haar onderzoek aan Wageningen Universiteit.
The main challenge to data sharing is organising data in a presentable and useful way | Stuart, 2018

In de spotlight
Tips voor versiebeheer
Als er continu aan de data gewerkt wordt, is het zinvol om een vorm van versiebeheer te introduceren waarmee je de wijzigingen goed kunt volgen. De simpelste manier van versiebeheer is het toevoegen van een nummer aan het eind van een bestand na elke belangrijke wijziging. Bijvoorbeeld experiment_021213_v2.doc.
Ook binnen één file kun je een vorm van versiebeheer toepassen. Bij het onderdeel Datadocumentatie kun je een case lezen waarin een onderzoeker versiebeheer opneemt in haar databestanden door een tabblad 'versiebeheer' toe te voegen.
Sommige programma's en virtuele onderzoeksomgevingen hebben een eigen automatische vorm van versiebeheer. Bij het werken met code/software, is het bijvoorbeeld zinvol om een tool zoals GitHub (n.d.), Git (n.d.) of SVN (Apache, n.d.) te gebruiken. Op het weblog Backlog staat een vergelijking tussen Git en SVN (Backlog, 2018).
Meer tips nodig?
- Bekijk de paragraaf van de CESSDA Data Management Expert Guide (n.d.) over versiebeheer.

Bronnen
Klik om te openen/sluiten
NB (2023): Some of these sources may no longer be maintained or may have moved URLs. The E4DS website is currently being updated; for archival reasons, we will not update this particular source list, but encourage you to search for them via your favourite search engine or to ask our coaches for their recommendations. Apologies for any inconvenience!
Apache (n.d.). Apache Subversion https://subversion.apache.org/
Backlog (2018, 4th of April). Git vs. SVN: Which version control system is right for you? https://backlog.com/blog/git-vs-svn-version-control-system/
Bulk Rename Utility (n.d.). https://www.bulkrenameutility.co.uk/Main_Intro.php
CESSDA (n.d.). Data Management Expert Guide. Data authenticity. https://www.cessda.eu/Training/Training-Resources/Library/Data-Management-Expert-Guide/3.-Process/Data-authenticity
DANS (n.d.). DataverseNL. https://dans.knaw.nl/nl/over/diensten/DataverseNL
Git (n.d.) https://git-scm.com/
GitHub (n.d.). https://github.com/
Patrick Vandewalle (n.d). http://pixeltje.be/
Stuart, David; Baynes, Grace; Hrynaszkiewicz, Iain; Allin, Katie; Penny, Dan; Lucraft, Mithu; et al. (2018): Whitepaper: Practical challenges for researchers in data sharing. figshare. Journal contribution. https://doi.org/10.6084/m9.figshare.5975011.v1
UK Data Service. (2017). Organising data. Retrieved from https://www.ukdataservice.ac.uk/manage-data/format/organising